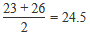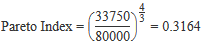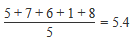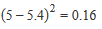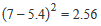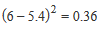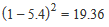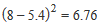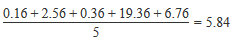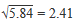Statistical and Mathematical Functions for Derivations - SuperCROSS
The following is a list of all the statistical and mathematical functions available for derivations in SuperCROSS.
The statistical functions compute various descriptive statistics for tabulation fields representing ranged (e.g. age) or bracketed (e.g. income) values using the frequencies found in the populated table.
| Function | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Exp | Exponential function where Exp = exp(x) | ||||||||||||
| Ln | Logarithm function where Log = ln(x) | ||||||||||||
| Round | Round function where Round = floor(x+0.5) | ||||||||||||
| Sqrt | Square root function where Sqrt = sqrt(x) | ||||||||||||
| Median | The middle value of a set or series of values (after data has been ordered from lowest to highest). For example, the median value of the set 22, 25, 34, 46, 90 is 34. If there are an even number of values in the set (and therefore no single middle value), then the median is calculated as the mean of the two middle values. For example, for the set 14, 16, 23, 26, 28, 33, the median is calculated as:
| ||||||||||||
| Percentile | The rank of a data point in a group of data. A percentile can only be derived from a set of numeric values. | ||||||||||||
| Pareto | The Pareto index is a measure of the breadth of income or wealth distribution. One of the simplest characterisations of the Pareto distribution, when used to model the distribution of income, is that the proportion of the population whose income exceeds any positive number x is: (xm/x)i Where:
Since a proportion must be between 0 and 1 inclusive, the index i must be positive. For example, to find the proportion of the population whose income exceeds $80,000 per year where the minimum income is $33,750 per year and the index is 4/3.
This indicates that approximately 31% of the population is earning more than $80,000 per year. | ||||||||||||
| Mean | The measure of the centre of ordinary arithmetic average (the sum of all values divided by the number of values). | ||||||||||||
| Variance | The variance is used as a measure of how far a set of numbers are spread out from each other, describing how far the numbers lie from the mean (expected value). Variance is calculated as the average of the squared differences from the mean. For example:
| ||||||||||||
| Stdev | Standard deviation is defined as the average amount by which values in a distribution differ from the mean, ignoring the sign of the difference. Standard deviation is calculated by taking the square root of the variance. For example, using the example above of the data set 5, 7, 6, 1, 8, the variance is 5.84, so the standard deviation is:
| ||||||||||||
| Asymmetry | Measures the lack or absence of balance (symmetry) about the mean. | ||||||||||||
| Skewness | A measure of the asymmetry from the normal distribution in a set of statistical data. The skewness value can be positive or negative, or even undefined:
| ||||||||||||
| Forecast | A forecast of a future (or past) value, based on the existing values. See Forecasting - SuperCROSS for more information about creating a forecast, and how forecasts are calculated. |