SuperCHANNEL can connect to a wide range of data storage facilities and Relational Database Management Systems (RDBMS). However, the original data source may not be ideal as direct input to SuperCHANNEL for a number of reasons:
-
The data in the original data source may not be clean. SuperCHANNEL enforces referential integrity and unclean data leads to rejected records and unexpected values added to classifications.
-
The data in the original data source may not be complete. For instance, classification data may be missing.
-
The data in the original data source may require application of business rules to be correctly interpreted.
-
There may be a need to derive additional data items to satisfy the business output requirement. Although this can be done downstream in the SuperSTAR client tools, it is often more logical to pre-calculate such items and incorporate them directly into the SuperSTAR database.
-
The original data source may not be in a star-schema format. Although this can sometimes be overcome by design within SuperCHANNEL, it is preferable to deal with an input star-schema to minimise design effort and improve sxv4 build performance.
For these reasons, it is typically necessary to create an intermediate staging database.
In some cases the effect of a staging database can be achieved by creating views over the original source, rather than by creating a separate physical staging database.
The ideal staging database would be in a star-schema format containing clean data to meet the business output requirements. When this is the case, SuperCHANNEL processing efficiency can be optimal (for instance, cleansing actions can be turned off).
The staging database is likely to provide input for more than one SuperSTAR database design, for example there may be an additional business requirement to provide a SuperSTAR database that contains data only for persons from a census collection, rather than the typical household-family-person content.
Guidelines
For best results using SuperCHANNEL, follow these recommendations when creating your staging database.
|
Recommendation |
Explanation |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
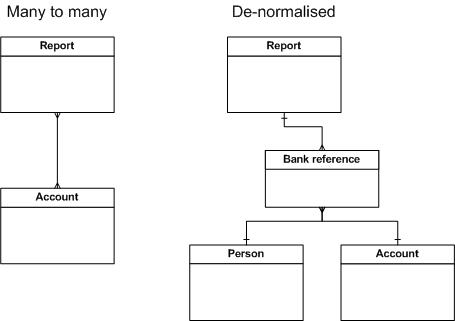
Avoid many-to-many relationships |
Many-to-many relationships are not directly supported by SuperSTAR as they can slow table searches. It is preferable to construct such relationships with a linking table so that the logical many-to-many relation is effected by two one-to-many tables. If your source data includes many-to-many relationships, consider what reports will be produced from the data. For example, the following database contains bank information. To avoid having the many-to-many relationship between the Report and Account table a Bank reference table has been created. This table contains bank information found in the Account table. When SuperSTAR scans for bank information it does not need to scan the Account table as the information it requires is in the Bank reference table.
|
||||||||||||||||
|
Ensure all fact tables are related to each other |
All fact tables must be related. If you have an orphan fact table (i.e. one that is not linked to any other fact table) then the SuperCHANNEL build process will complete, but no data will be visible through a SuperSTAR client. If you have unrelated fact tables then you must channel them to separate SXV4 databases. |
||||||||||||||||
|
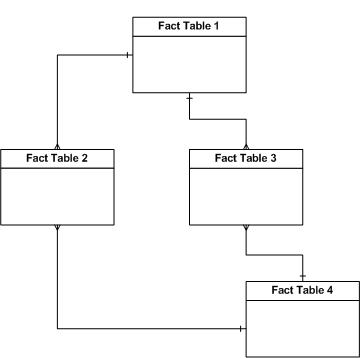
Avoid circular references |
No circular references between fact tables are allowed as this will produce different figures in cross-tabulation. For example, the join between Fact Table 2 and Fact Table 4 should not exist:
|
||||||||||||||||
|
Follow the SuperSTAR naming conventions |
Follow the recommended naming conventions. |
||||||||||||||||
|
Use integer data types for keys |
Where possible, keys should be of type integer. SuperSTAR joins are faster when primary-foreign key joins are integer based rather than string based. |
||||||||||||||||
|
Remove unnecessary columns |
The original source is likely to include columns that do not have any use in the SuperSTAR system under construction. Exclude these columns when you load data into the staging database. It is possible to exclude unnecessary columns in the SuperCHANNEL design stage, but the design effort is reduced if you exclude them from the staging database. |
||||||||||||||||
|
Remove leading and trailing spaces |
Remove any leading and trailing spaces when you load data into the staging database. Additional spaces have been known to cause issues with some SuperSTAR product features. Removing the spaces also avoids creating overly long classification labels. |
||||||||||||||||
|
Avoid null values in fact tables |
Data in fact table columns should not contain null values. SuperSTAR can handle null values, but it is much more useful in a business sense to remove these from the source by coding to a "dump code". |
||||||||||||||||
|
Remove unnecessary data |
When inserting data into the staging database, pay attention to any business rules that are necessary for correct interpretation of the original source, and remove any unnecessary data accordingly. For example, if there are records that exist in the source but have a logical delete flag set, exclude these records from the staging database. |
||||||||||||||||
|
Avoid unnecessary primary keys |
Do not use primary keys in the staging table unless:
If none of the above apply, remove the primary key constraint from the column in the staging schema. |
||||||||||||||||
|
Avoid primary keys of 'complex' data types |
Try to limit primary keys to columns with text or integer related data types. Avoid setting columns with the following data types to primary keys:
In general, integer primary keys are preferred for performance reasons. |
||||||||||||||||
|
Avoid compound primary/foreign keys |
Sometimes SuperCHANNEL will be slow if it has to check record integrity for tables that have compound primary/foreign keys (keys that are made up of more than one column). |
||||||||||||||||
|
Use only supported data types |
SuperCHANNEL only supports the following data types:
|