
Overview - Perturbation
If you are publishing data then you’ll know how important it is to protect the confidentiality of any individuals in that data.
In many countries, including Australia, there can be serious legal consequences to releasing data that allows individuals to be identified. Additionally, if organisations do inadvertently release data that allows individuals to be identified, public trust is compromised.
On the other hand, if organisations do not release any data, or release only prescribed views of data, then open data transparency is compromised, and the potential economic and social benefits are lost.
Removing Sensitive Fields is Not Sufficient
Simply removing “Personally Identifiable Information (PII)”, such as names and addresses, does not eliminate the risk that someone could be identified in your data.
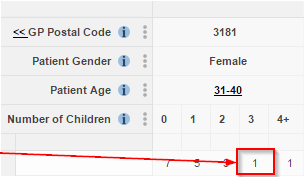
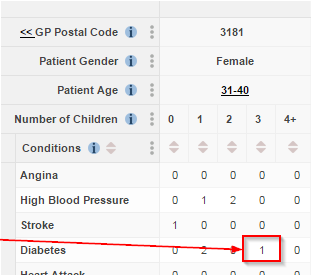
If someone knows some facts about a person in your data, they may be able to use these facts to identify that individual. Once they have found someone, they can then use this to find out other confidential information about the individual.
For example:
- I know that my neighbour’s health records are included in a released dataset.
- I know that she has three children
- I know that she is aged in her mid-30s
As only one person in the dataset fits these criteria, I can be confident I have identified her.
It is now easy for me to discover confidential information about her medical history.
Typical Approaches to Disclosure Control
Traditionally, data publishers have used two main strategies to tackle this problem (or a combination of these two strategies): changing cell values, and concealing cell values. Both approaches have advantages and disadvantages.
Changing Cell Values
With this approach, some or all of the cell values are changed to protect sensitive data. For example, values might be randomly rounded up or down.
Possible disadvantages to this approach:
- If cell contents are randomly adjusted, then different users might get different results for the same query.
- Randomly adjusting values might reduce the usefulness of the data, or introduce bias into the results.
Concealing Cell Values
With this approach, cells containing sensitive data are concealed/suppressed. This approach has a number of drawbacks:
| Reduced Usefulness | If too many cells are concealed then this will reduce the usefulness of the data, making it harder to see trends and patterns. |
|---|---|
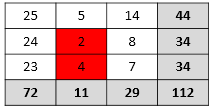
| Consequential Cell Suppression | Often, it is necessary to conceal other cells as well, otherwise the column and row totals might reveal the real values of the suppressed cells. For example, suppose the data publisher chooses to suppress all cell values under 5. In the following example, that would mean suppressing the values 2 and 4 (highlighted in red):
However, in this case it is not enough to hide only these cells, because the totals, such as the row total of 34 in the row containing the suppressed cell, allow users to work out the true cell values of the suppressed cells. |
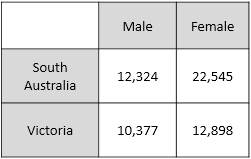
| Differencing Attacks | Cell suppression does not prevent differencing attacks. This type of attack involves creating multiple tables and using the difference in values between them to obtain the true value for a particular field item For example:
|
How Perturbation is Different
Space-Time Research has worked in collaboration with government agencies around the world to develop a unique solution that addresses privacy concerns without compromising the flexibility and utility of a self-service data dissemination platform.
Our solution, perturbation, prevents identification of individuals by adjusting cell values. However, it has a number of advantages over the above techniques:
| Controlled Adjustments | Perturbation makes controlled adjustments to cell values, rather than just randomly changing them. The adjustments themselves are carefully calculated to avoid introducing bias. |
|---|---|
| Consistency of Output | Values are adjusted consistently.
|
| Highly Configurable | The administrator has full control over exactly how values get adjusted. The perturbation configuration is extremely flexible and can be tailored to meet specific requirements. |