
When you start a build in SuperCHANNEL, the progress log displays automatically.
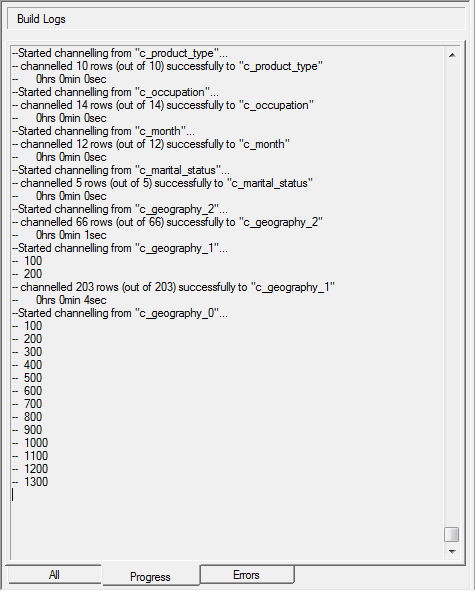
Log Overview
The log messages start with details of the exact build of SuperCHANNEL in use, followed by the command line options passed to the SNU command to run the build:
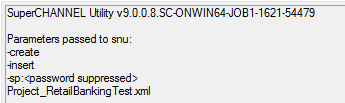
In this example, the corresponding SNU command would be:
snu -create -insert Project_RetailBankingTest.xml
The next section contains information messages about the preparation for the database build:

This is followed by details of the connection to the source database, including the driver used and the time taken to connect:

The next section of the log shows details of the connection to the target database:

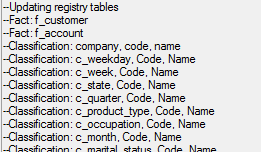
The Updating registry tables section contains details that will be written into the registry tables in the target database:
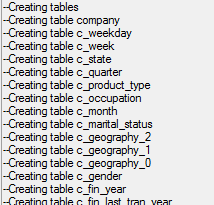
The Creating tables section shows the tables that are created in the target database:
The next section shows data insertion from the classification tables to the target database (the build process inserts data into the classification tables first, before channelling from the fact tables, so that it can perform a referential integrity check against these tables when it inserts the data from the fact tables).

Messages like the following indicate how many rows from the source table have been channelled into the target:
-- channelled 2 rows (out of 2) successfully to "company"
Once SuperCHANNEL has finished inserting data for the classification tables, it begins populating the fact tables.
In this case SuperCHANNEL has used Batch Insertion, and all rows from source have been channelled to the target:
It is important to check the logs after each build to confirm that the number of rows channelled for each table matches the number of rows in that table. If any rows are missing, for example: channelled 454282 rows (out of 454286) then this may indicate issues with your source data.
SuperCHANNEL also displays the total number of cleansing actions found during the run and indicates that the build is complete:
Other Log Messages
The following are some of the other messages that you might see in the output from a successful build.
Value out of range
The message Value out of range indicates that there are data types in the source data that have not been mapped to a known data type for channelling to the target. SuperCHANNEL automatically maps these to OTHER, which means that the data for these columns will not be inserted into the target.
Connecting to target database jdbc:sxv4:D:\Databases\STR\RetailBanking
Time to connect: 3 second(s)
Time handling target database metadata: 0 second(s)
WARN 11:09:05:891 [main] XMLReader3_0 - Caught exception 'Value out of range. Value:"2147483647" Radix:10'
while processing MAPPING element with SOURCETYPE '-3' and TARGETTYPE '2147483647'. Mapping to 0 instead.
WARN 11:09:05:891 [main] XMLReader3_0 - Caught exception 'Value out of range. Value:"2147483647" Radix:10'
while processing MAPPING element with SOURCETYPE '-2' and TARGETTYPE '2147483647'. Mapping to 0 instead.
WARN 11:09:05:892 [main] XMLReader3_0 - Caught exception 'Value out of range. Value:"2147483647" Radix:10'
while processing MAPPING element with SOURCETYPE '2004' and TARGETTYPE '2147483647'. Mapping to 0 instead.
WARN 11:09:05:893 [main] XMLReader3_0 - Caught exception 'Value out of range. Value:"2147483647" Radix:10'
while processing MAPPING element with SOURCETYPE '2005' and TARGETTYPE '2147483647'. Mapping to 0 instead.
In most cases, the columns concerned would not contain data that would be useful in the target database.
Check the Data Type Mapping tool for further information. You should check that all the data types in your source data have been correctly mapped to ensure that all important data is correctly mapped.
getSchemas failed
The getSchemas failed message appears in the Errors log. It occurs when a connection to the database is made using the jdbc:odbc bridge. This is a Type 1 JDBC driver, which does not support connections between tables.
Warning - getSchemas failed
SQLException: [Microsoft][ODBC Microsoft Access Driver]Optional feature not implemented
Warning - getImportedKeys failed
SQLException: [Microsoft][ODBC Driver Manager] Driver does not support this function
Warning - getPrimaryKeys failed
SQLException: [Microsoft][ODBC Driver Manager] Driver does not support this function
When using the jdbc:odbc bridge, you must explicitly create references between tables in the SuperCHANNEL GUI. The messages will still appear for builds using this driver even if all references have been created, but in this case the messages can be ignored.
Cannot set cleansing action to ADD for a hierarchical classification reference: defaulting to SKIP
Messages of this type are informational, rather than errors.
ERROR 11:30:04:210 [main] XMLReader3_0 - Warning - TargetColumn.setCleansingAction: Column 'Area': Cannot set
cleansing action to ADD for a hierarchical classification reference: defaulting to SKIP
If a fact table value for a hierarchical classification is not found in the classification table, it cannot be inserted because the rest of the links in the hierarchy are not known (the fact table value is always the bottom value in the hierarchy). The cleansing action is automatically changed to "skip" and the build continues.
It is not possible to use batch mode to load table
This message displays when SuperCHANNEL is unable to use batch mode to process one of the fact tables, because the source data does not permit use of this mode.
In this case, SuperCHANNEL uses classic mode, and displays details of the conditions that prevented it from using batch mode.
It is not possible to use batch mode to load table "F_Customer".
If you want to use batch mode processing for this table please consider changing the table definition
to avoid use of the following unsupported feature(s):
See Batch Insert Mode for more information about batch mode and classic mode.
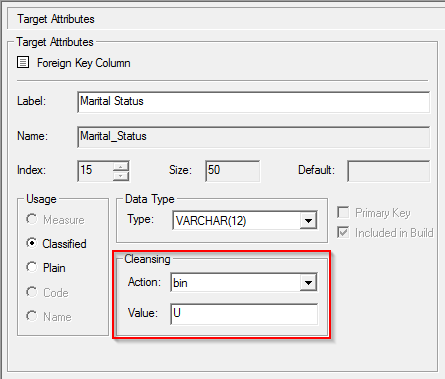
Action: binning value of column
Cleansing actions allow you to automatically clean up some of your source data when building your SXV4 database.
One of the available cleansing actions is "bin": when SuperCHANNEL encounters a value in a fact table that is not one of the available classifications, it will automatically convert (or "bin") the value for that record to a specific classification. This action is typically used to convert empty or incorrect incorrect values in the fact table to a catch-all classification like "Unknown" or "Not Applicable".
If you have configured one or more fact table columns to use the "bin" cleansing action, then you may see messages similar to the following in the logs:
binning value of column 'Marital_Status' from '' to 'U' on row 269192
-- channelled 269193 rows (out of 269193) successfully to "F_Customer"
-- 0hrs 0min 4sec
In the example shown here, the message indicates that in row 269192 of the fact table, SuperCHANNEL found a value of ' ' (i.e., an empty value) in the Marital_Status column. As this is not one of the valid classifications for this column, it has automatically been binned to 'U' (Unknown).
SuperCHANNEL has taken this action in accordance with the cleansing action configured for this column:
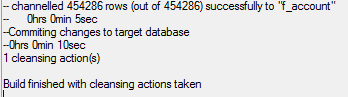
A message at the end of the build notes the total number of cleansing actions:
-- channelled 454286 rows (out of 454286) successfully to "F_Account"
-- 0hrs 0min 5sec
--Commiting changes to target database
--0hrs 0min 10sec
1 cleansing action(s)
Build finished with cleansing actions taken
Build Progress Indicator
The log files show the build progress using a record count. By default, this count updates after every 100 records are processed:

You can change the default increment by editing the str.progress.report.interval parameter in the SuperCHANNEL configuration file, config.txt .
Error Log
If there are errors in the build, they display on the Errors tab.
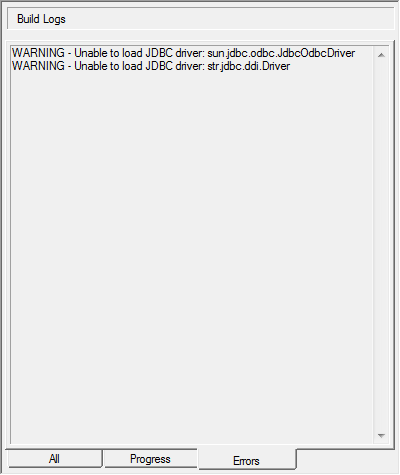
In the following example there are two warning messages:
WARNING - Unable to load JDBC driver: str.jdbc.komodo.Driver
WARNING - Unable to load JDBC driver: str.jdbc.ddi.Driver
The messages indicate that two drivers that were specified in the SuperCHANNEL configuration, config.txt , could not be found. Both of these are WingArc drivers and are typically not required:
-
str.jdbc.komodo is the driver required for connection to the deprecated SXV3 format, and is only available in the 32-bit version of SuperCHANNEL.
-
str.jdbc.ddi is the driver for connection to data in DDI format. This driver is only available in an extended DDI version of SuperCHANNEL.
If you are not using SXV3 or DDI then these errors can be ignored.
Error Messages
Target Schema validation failed: No CODE column defined for classification table
If SuperCHANNEL encounters a classification table without a Code column, it displays the following error message:
ERROR: Cannot proceed with build: Target Schema validation failed.
Found 3 errors:
(1) No CODE column defined for classification table 'Occupancy'
(2) No CODE column defined for classification table 'Heating'
(3) No CODE column defined for classification table 'Dwelling Type'
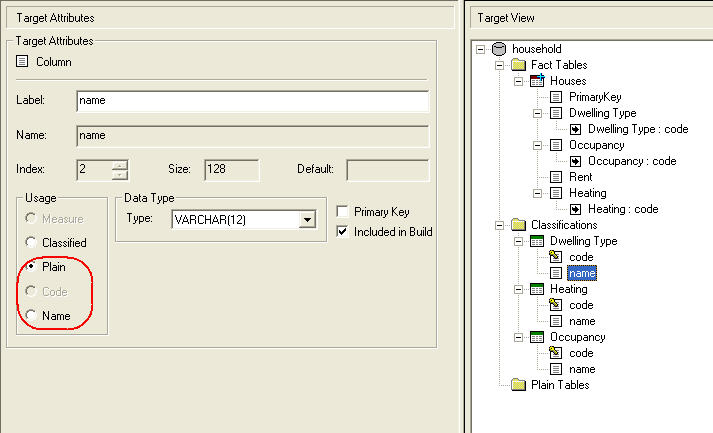
To resolve this issue, use the Target Attributes pane to specify which column in the classification table is the Code column:
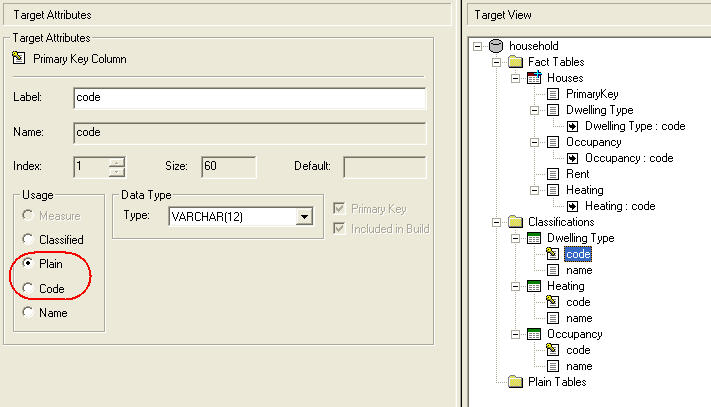
Target Schema validation failed: No NAME column defined for classification table
If SuperCHANNEL encounters a classification table without a Name column, it displays the following error message:
ERROR: Cannot proceed with build: Target Schema validation failed.
Found 3 errors:
(1) No NAME column defined for classification table 'Occupancy'
(2) No NAME column defined for classification table 'Heating'
(3) No NAME column defined for classification table 'Dwelling Type'
To resolve this issue, use the Target Attributes pane to specify which column in the classification table is the Name column:
SQLException
If there are any SQLException error messages displayed in the Errors tab, then this indicates a serious data problem. In most cases this type of error is caused by issues with the source data.
For example:
BatchDispatcher encountered SQLException: -- Could not look up compound keys ( 7772 ) in index Tables/F_Customer/Indexes/PrimaryKey while inserting data into table F_Account, column: ( FK_Cust_Key ), join: Joins/F_Account_20_F_Customer_0_Joins
In this example, there are two fact tables (F_Accounts and F_Customer) linked with a primary key/foreign key relationship. This error message indicates that the F_Account fact table has a record with a foreign key value of 7772 that could not be found in the primary key column of the F_Customer table. This either means that a record is missing from the F_Customer table in the source or that the record with that ID has been skipped for some reason.
When troubleshooting this issue, a good next step is to check the Progress logs for any issues. For example:
Using Batch Insertion for table: F_Customer
--Action: skipping at column "Area" found invalid value "9090" on row 0...skipped
-- channelled 269191 rows (out of 269192) successfully to "F_Customer"
-- 0hrs 0min 3sec
--Started channelling from "F_Account"...
Using Batch Insertion for table: F_Account
-- channelled 0 rows (out of 19902) successfully to "F_Account"
-- 0hrs 0min 0sec
--Commiting changes to target database
--0hrs 0min 4sec
120 cleansing action(s)
In this case we can see that one of the records in the F_Customer table has an invalid post code in the Area column. As this is a hierarchy, which does not support the add to classification cleansing action, the row has been skipped: channelled 269191 rows (out of 269192) successfully to "F_Customer",
As a result, SuperCHANNEL has been unable to link the two fact tables together, and has skipped the entire F_Account table: channelled 0 rows (out of 19902) successfully to "F_Account"
The solution here is to resolve the issue in the source data by doing one of the following:
-
If the value of
Areain theF_Customerrecord in question is valid, add it to the classification tables (with a suitable foreign key to the next level in the hierarchy). -
If the value of
Areain theF_Customerrecord is not a valid postcode, change it to a valid value.
Invalid Column Index
If you attempt to channel a Textual Data Definition (TDD) that contains an incorrect delimiter in any of the files this will result in an SQLException: Invalid column index.
For example:
Using Batch Insertion for table: F_DEM_SAMPLE
-- 972600Exception thrown in batch inserter for table 'F_DEM_SUPP_1'
java.sql.SQLException: Invalid column index.
SQLState: S0013
java.sql.SQLException: Invalid column index.
at str.jdbc.sctextdriver.JDBCLayer.SCTextResultSet.getString (SCTextResultSet.java:426)
at str.realtimechanneler.ResultSetIterator
$StringColumn.populatePreparedStatement(ResultSetIterator.java:204)
at str.realtimechanneler.ResultSetIterator.populatePreparedStatement (ResultSetIterator.java:144)
at str.realtimechanneler.BatchInserter.run(BatchInserter.java:85)
-- 973400Exception thrown in batch inserter for table 'F_DEM_SUPP_2'
java.sql.SQLException: Invalid column index.
SQLState: S0013
java.sql.SQLException: Invalid column index
at str.jdbc.sctextdriver.JDBCLayer.SCTestResultSet.getString
(SCTextResultSet.java:426)
The solution here is to use the correct delimiter in your TDD files.