
Target Attributes - SuperCHANNEL
The Target Attributes pane allows you to change attributes for the columns and tables in the SuperSTAR database.
To display the Target Attributes pane, click the icon on the toolbar:
The attributes shown will depend on what is currently selected in the Target View. For example, different attributes are shown if the currently selected item is a database, fact table, or column.
Database Attributes
These are shown when you select a database in the Target View:
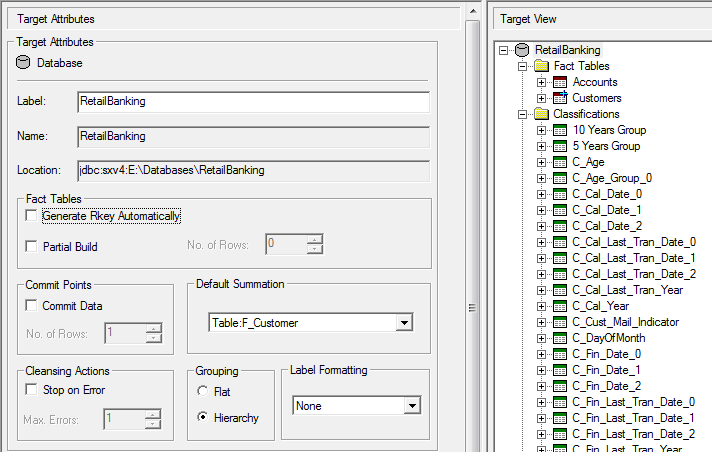
The database attributes for a target schema are available at any time during the design of a target schema.
| Attribute | Description | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Label | The database label. By default, this is set to the target database filename (without the .sxv4 extension). You can change the label if you wish, although this label is not used in the SuperSTAR clients (you can set the display name for the database to use in the clients when you add the database to the catalogue in SuperADMIN). | ||||||||
| Name | The database name. This is set automatically based on the target database filename and cannot be changed. | ||||||||
| Location | The location of the target database file. This cannot be changed. | ||||||||
| Whether to generate Rkeys automatically for this database. See Automatically Generate R Keys for Perturbation - SuperCHANNEL for more details. The Partial Build setting determines the number of rows to include when building the database:
This option is designed to allow you to test your configuration without having to build the entire SXV4. It is particularly useful if you have a very large source database. You can configure SuperCHANNEL to run a partial build with just a small number of rows to check that you are happy with the output. Once you are satisfied with the design of the SXV4 you can turn off the partial build and build the entire database.
When using the Partial Build option you may see errors in the logs indicating that some of the foreign key constraints did not succeed. This is typically because one of the child tables references a row in a parent table that was not included in the partial build.
| ||||||||
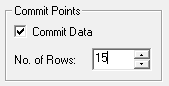 | The number of records channelled before changes are committed to the target database. This setting affects disk usage. See Resource Considerations - SuperCHANNEL for more information.
There is also a Commit Points setting for each fact table. If this is configured at the fact table level in addition to the database level, then the fact table setting takes precedence over the setting at the database level.
| ||||||||
| The maximum number of cleansing actions allowed for a database build. If you select the Stop on Error check box, then the build process will stop if it reaches the specified number of cleansing actions. | ||||||||
| The default summation used during tabulation. This can be either:
The drop-down list shows all the fact tables and measure columns available in the database. You can also tell what is currently the default summation by looking for the + icon in the Target View:
| ||||||||
| The capitalisation of the table and column labels:
When you select one of the options, all the target labels will be changed immediately. If you subsequently edit the labels, then your chosen capitalisation option will not be applied to your modified labels automatically. If you change some of the labels and want to reapply your chosen label formatting, you must go back to the Target Attributes and reselect one of the formatting options. | ||||||||
| The default grouping mode for the target database.
The selected grouping mode will be applied by default. You can manually modify the grouping by editing the settings in the Grouping pane. If you use the Reset Grouping option in the Grouping pane then the groupings will be reset to either flat or hierarchical based on this setting.
|
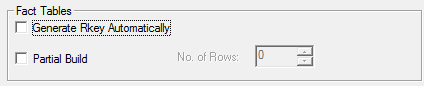
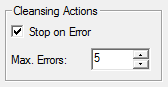
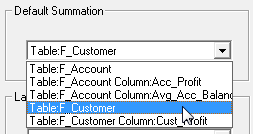
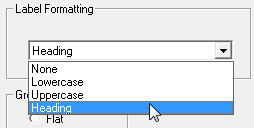
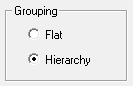
Table Attributes
These are shown when you select a table in the Target View:
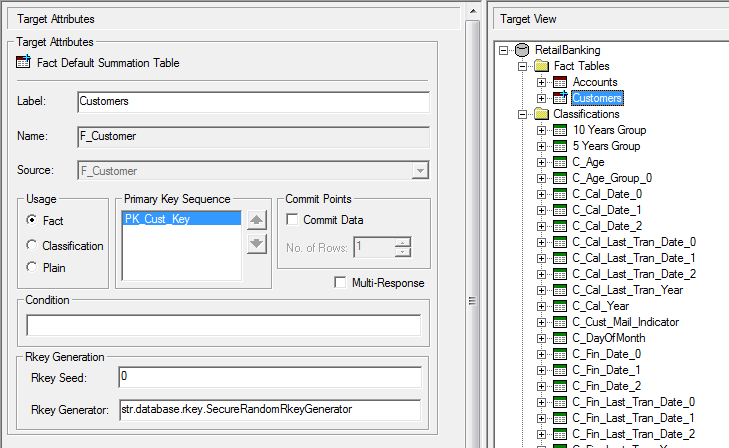
| Attribute | Applies To | Description |
|---|---|---|
| Label | All table types | The display name for this table.
|
| Name | All table types | The table name. This is based on the source database and cannot be changed. |
| Source | All table types | The name of the source table in the source database. This cannot be changed. |
| Usage | All table types | The table type (Fact, Classification or Plain). |
| Condition | All table types | A SQL WHERE or ORDER BY clause that will be executed when the database build is run. For example, you might use this to sort your classification tables.
The following example shows a compound WHERE clause:
Any references to columns must use the column Name attribute, not the Label:
|
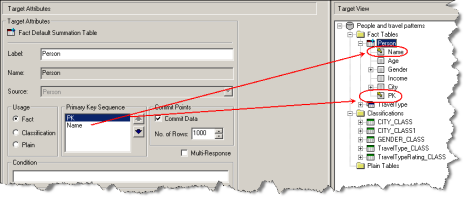
| Primary Key Sequence | Fact tables only | The sequence of primary keys, if the fact table has more than one primary key.
Select one of the keys in the list and click the up or down arrow to move it up or down. The primary key sequence is important for performance reasons:
|
| Commit Points | Fact tables only | The number of records channelled before changes are committed to the target database. If you set this value at the fact table level, it will override any commit points configured at the database level. |
| Multi-Response | Fact tables only | Whether or not the fact table is a multi-response table. Select the check box to configure the fact table to be a multi-response table. Multi-response tables are indicated in the Target View with a multi-table icon:
|
| Column Usage | Classification tables only | The names of the columns used for the Code and Name. All valid classification tables must have one column whose usage is set to Code, and another column whose usage is set to Name. You cannot edit this from the table Target Attributes pane. To change the column usage you need to select the individual columns and specify which one is which. |
| Totals Appropriate | Classification tables only | Whether to allow totals for this classification table. This setting is designed for situations where it does not make sense to generate totals based on this classification (for example, you may have a time series database where it does not make sense to sum across years). The setting currently applies to SuperWEB2 only; it does not affect totals in SuperCROSS:
|
| Rkey Generation | Fact tables only | The seed and generator to use when generating Rkeys for this fact table. These settings only appear if the Generate Rkey Automatically check box is selected. See Automatically Generate R Keys for Perturbation - SuperCHANNEL for more details. |

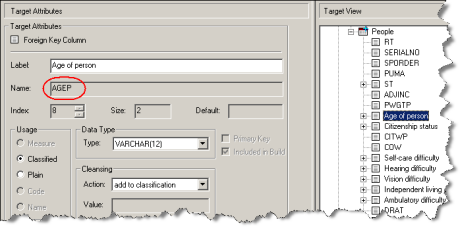
Column Attributes
These are shown when you select a column in the Target View:
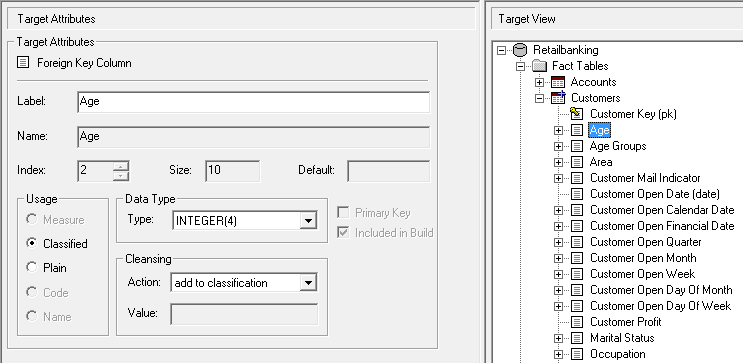
| Attribute | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Label | The display name for this column.
| ||||||||||||
| Name | The column name. This is extracted automatically from the source database and cannot be changed. | ||||||||||||
| Index | The column index from the source database. This cannot be changed. | ||||||||||||
| Size | The column size from the source database. This cannot be changed. | ||||||||||||
| Usage | The column usage.
| ||||||||||||
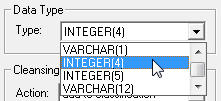
| Data Type | The column data type. You can change the data type by selecting a new value from the drop-down list:
| ||||||||||||
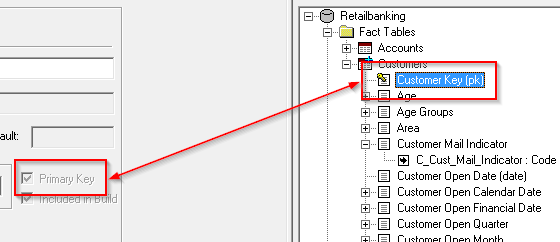
| Primary Key | Indicates whether or not this column is a primary key. You can also identify which columns are primary keys by looking for the key icon in the Target View.
Primary keys are used when linking tables. For example, if there are multiple fact tables, one of the fact tables must has a foreign key that is linked to the primary key of the other fact table. In addition, each Classified column in the fact tables must be linked to the primary key of its classification table (the Code column). | ||||||||||||
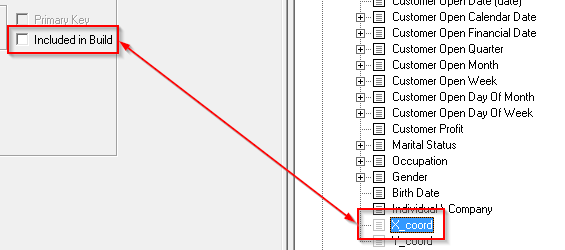
| Included in Build | Indicates whether or not the fact table column is included in the build. Excluded columns appear in the Target View but are greyed out:
Any column with the data type OTHER is automatically excluded from the build. You will need to change the column data type in order to include it in the build. You should always exclude columns from the build if their data is not required in the target database. This helps to optimise build times and keep database sizes to a minimum. | ||||||||||||
| Cleansing | The action to take when the build fails to match a value in the fact table column with the set of possible values in the linked classification table. For example, the Gender column might be linked to a classification table containing the codes M (Male), F (Female), and U (Unknown). What should SuperCHANNEL do if it encounters an empty value for this column in one of the records in the fact table? You can choose from the following cleansing actions:
|
Plain table columns are not included in a database build. The attributes for a plain table and its columns are not useful until the table has been redefined as either a fact or classification table.