
The SuperCROSS ColourMatrix feature makes it easy to visualise patterns in your data. This section explains the statistical basis that SuperCROSS uses to colour the table.
Overview
One of the most common user tasks when working with tabular data is identifying and quantifying correlations and associations. Fundamentally, if two measures are associated, we have the opportunity for relationships to exist, and insight to be garnered.
To find an association, we start by calculating what the data would look like in the absence of any pattern. That is, we determine the expected number of counts in each cell, based on a simple assumption that the values are distributed homogeneously.
Associations will manifest as unexpected patterns in the data: cells (or groups of cells) that are significantly higher (or lower) than expected.
There are a number of statistical tests that can be applied to tables to ask questions such as:
-
Do the cell values differ from the homogeneous base case?
-
Is there a pattern?
-
How strong is the pattern?
A positive result on a test for existence is merely based on the statistical likelihood of seeing such an association appear in the data by random chance. The strength of an association relates to the statistical effect size, and can be considered (to some extent) the predictability of the associative outcome.
SuperCROSS provides a simple but robust mechanism to assess these question: ColourMatrix
How is ColourMatrix Different from ColourVIEW?
ColourMatrix replaces ColourVIEW, which was available in previous SuperCROSS releases.
ColourVIEW was based on a simple expectation ratio: each cell value was divided by the expected cell value to determine how far it deviated from the expectation. However, this algorithm did not take into account the size of deviation from the expectation.
For example, having a value of 3 in a cell when expecting 2 (an overestimation of 1 unit) was given the same score as having an excess of 250 when expecting 500 (an over representation of 50% or an expectation ratio of 1.5). If there were an expectation of 750 and 500 were encountered then the expectation ratio would be 0.66. The relationship between these two differences is not readily apparent.
The new algorithm retains the simple, visual interface while being much easier to interpret and providing much more information about the size of any over or under representation.
It also conforms to simple, well documented statistical rules.
Algorithm Overview
The ColourMatrix algorithm is based on the χ2 (“kye squared”) test for homogeneity and independence. As this test is only uni-directional (it does not reflect under or over representation in the table), it is supplemented with a variant of analysis of standardised residuals (Haberman, 1973).
The ColourMatrix algorithm is based on the following assumptions:
-
Tables consist of categorical/nominal (frequency) data in mutually exclusive categories.
-
The data represents a random sample of n independent observations.
-
The expected frequency in each cell is 5 or greater.
The third assumption is the subject of much debate in the community. How conservative (and stringent) should this assumption be?
Fundamentally, the association tests here rely on a smooth approximation to what is, in fact, a discrete distribution. Generally, an expectation of 5 or greater ensures that this approximation is acceptable. If cells have a lower expectation than 5, the chi-squared distribution of probabilities may not provide a truly accurate representation.
The algorithm first calculates the expected values for each cell (under the assumption of a completely homogeneous set).
It then undertakes three key statistical tests and provides the following feedback:
-
Cells are coloured to indicate how close they are to the expected value.
-
If the user selects the Cluster option, then the table is reordered to group together cells with similar levels of deviation.
-
Textual results are provided for the tests for association existence (using the χ2 test) and the measure of association strength (using Cramer’s Φ, with Cohen’s w as benchmarked values).
Notation
This section uses the following notation to convey techniques:
-
f represents a cell count, with the dimensionality of the resident cube dictated by the number of subscripts. For example, fij comes from a 2-dimensional cross tabulation of i rows and j columns; whereas fijk has i rows, j columns, and k wafers.
-
The marginals (totals and subtotals) are denoted by a dot in the relevant subscript. For example:
-
f.j is the jth column total.
-
fi.. is the wafer total of the ith row.
-
f… is the grand total of a 3 dimensional data cube.
The Expected Value
Association is naturally expressed between only two variables. As such, examples are often based on a 2-dimensional cross table. Yet this ignores the natural hierarchy in modern data storage systems: the data cube. A data cube is essentially a series of cross-tables (wafers) layered on top of each other.
Describing the meaning of an association within a single layer is simple: an association is between the variable represented by the rows and the columns. However, describing the meaning of an association within a cube can be problematic.
It might be between the rows and columns with the wafer irrelevant. It might be between the column and the row/wafer. It could be weak, but across all three, or strong but only between two variables. As such, “strength” can lose meaning across cubes.
Calculating the Expected Value
Under an assumption of no association, either homogeneity or independence, the expected cell value (Eij ) is deduced from the relevant row, column, and wafer totals:
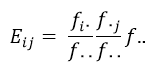
This relationship is expressed in a way to highlight its construction from simple joint probabilities. To extend to cubes (and dimensionally beyond), we can use the simple generalisation:
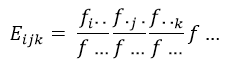
The ColourMatrix algorithm uses this to generate the expected cell counts for a cube that will match the top two aggregated dimensions (i.e. grand total and wafer totals for cubes, grand total and row/column totals for cross tables will be satisfied identically).
Standardised Residuals
Armed with an expectation value, we can generate a data cube of the same dimensions as the original cube, and propagate it with expressions for the deviation of the data, from the expectation.
For each cell, the rule for this is
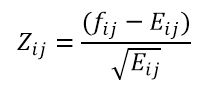
This form is selected for a number of specific reasons:
-
It will be standardised.
-
It is negative for table values that are less than we expected, and positive of cells that are over–represented in the data.
-
It is symmetric, and centred on zero.
-
It is interpretable, in that the standardisation means that an independent selection of these values will conform to a Z-distribution.
Colouring the Cell
The standardised residual for each cell is used to colour the cell. The colour is based on standard statistical interpretation of the number.
Typical values for the Z standardised variables are as follows:
-
They will average 0
-
The modal value will be 0.0
-
50% will be positive, 50% will be negative.
-
~70% will be between (-1,1)
-
~95% will be between (-2, 2)
-
less than 1% will be outside (-2.6,2.6)
These relationships are well known, and can be derived directly via numerical function, or through the use of look-up tables. In the same way, the probability of exceeding values (p-values) can readily be derived across an entire cube.
Testing the Association
If there is genuinely no association across the variables, then the standardised residuals can be assessed as a master set with predictable outcomes. The sum of their squares will conform to a χ2 distribution with the relevant degrees of freedom:
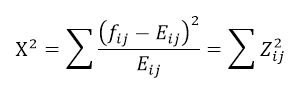
To test the existence of a possible association, we attempt to reject the possibility that a value could be as large as it is under chance alone. While we do not expect that every value in every cell will precisely match the expectation, each cell should be within the noise of the expectation. We also understand how an aggregate of squared Z distributed values should be distributed according to a χ2 distribution. The critical value is the χ2 value for the relevant degrees of freedom.
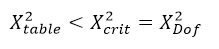
The degrees of freedom relate to the construction of the cube and its ability to maintain the relevant and required marginal totals. If the amount of deviation we measure is less than this critical value, then there is no evidence to suggest that the table is significantly different to the one we would expect to see if there were no association between variables.
For a cross tabulation, the degrees of freedom is given by
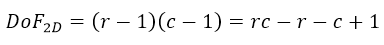
where r is the number of rows, and c the number of columns. For a cube this becomes
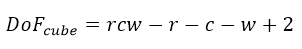
where w is the number of wafers.
This can be generalised to N dimensions as
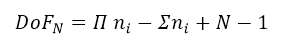
where N is the dimensionality of the cube, and ni are the sub-dimension counts.
For the Z values, there exist calculations and look-up tables for determining the critical values of χ2, and reporting the likelihood of such a combination of residuals arising by chance (p–values). Given a statistical likelihood that a χ2 value should arise, if it is deemed likely that there is a true association within the cube or table then the standardised residuals guide the analysts in finding cause for why (or where) we were compelled to reject the hypothesis that there was no association within the table. The largest absolute residual values contribute the most to the finding of an association.
How Strong is the Association?
Modern data tools are designed to move and display large volumes of data. Consequently, they are capable of resolving very small effects to great statistical significance. It is therefore important to determine the potential size or strength of any detected association.
The use of a χ2 value needs in some way to be corrected for the volume of data involved, determining strength. When there are only two variables at hand, the greatest association can be easily visualised (it is when all the data resides on the diagonal). We can go further than this, and deduce the maximum value that a χ2 statistic can be for a given table. Scaling our determined metric by this value gives us a standardised metric of association strength.
This is known as Cramer’s Φ (or ΦC)
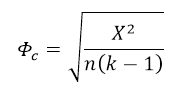
where k is the smaller of the number of columns or rows and n is the total, independent contributor count. This value depends on the size and shape of the original table. To some extent it can be standardised by reporting Cohen’s w .
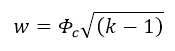
There is an accepted range for w , as follows:
|
Effect Size |
Range (w) |
|---|---|
|
Small |
0.1≤w<0.3 |
|
Medium |
0.3≤w<0.5 |
|
Large |
0.5≤w |
Clustering the Table
The standardised residuals are configured such that any group should have a net sum of zero. Taking each wafer, row or column in turn, we can produce a measure of that sum as a metric. Those that are positive are generally over-represented in the set, while a negative score suggests under-representation.
Re-ordering the rows and columns (when the user selects the Cluster option) to place the most positive scores in the upper left corner generates further insights into the potential underlying association.